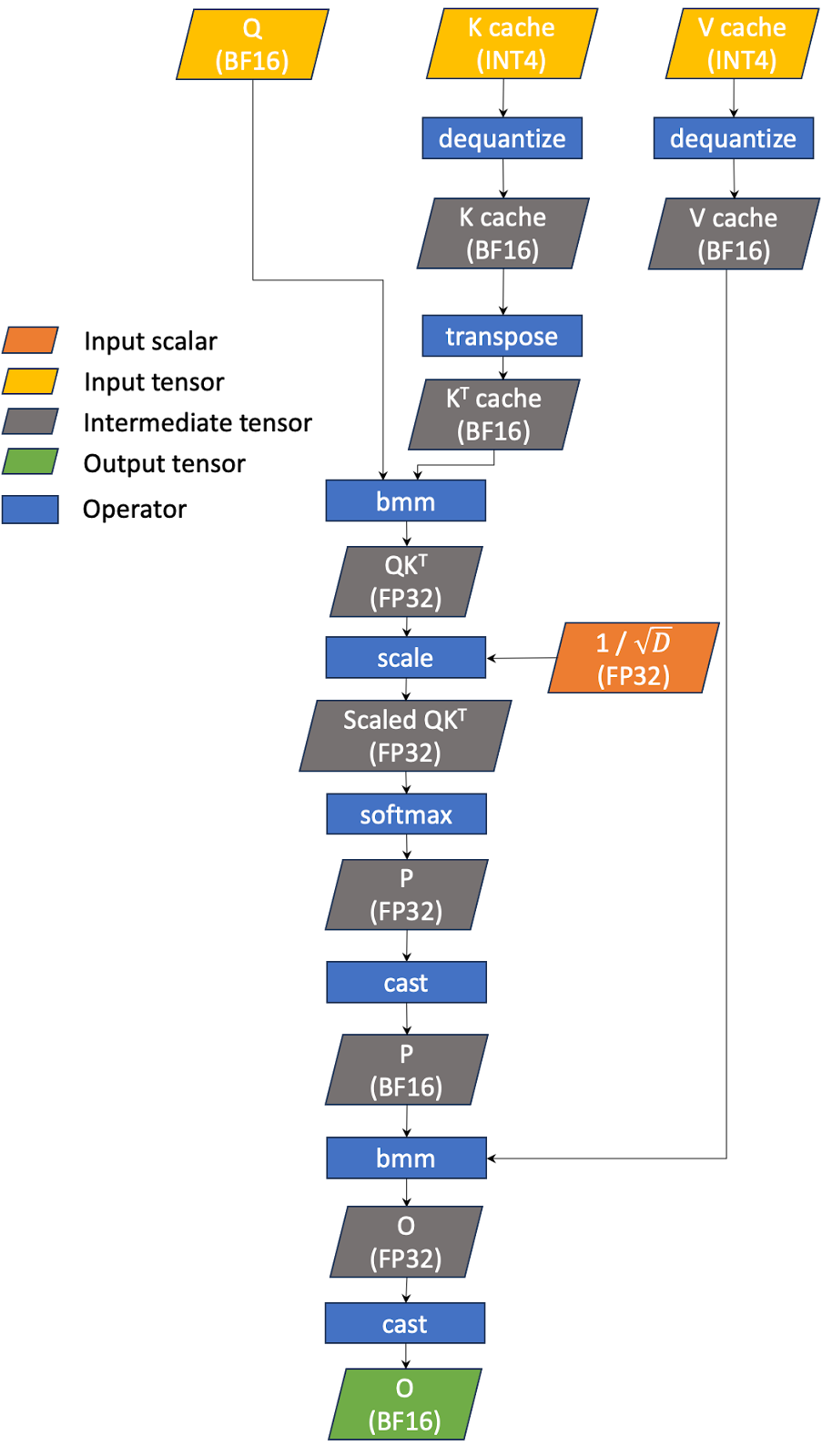
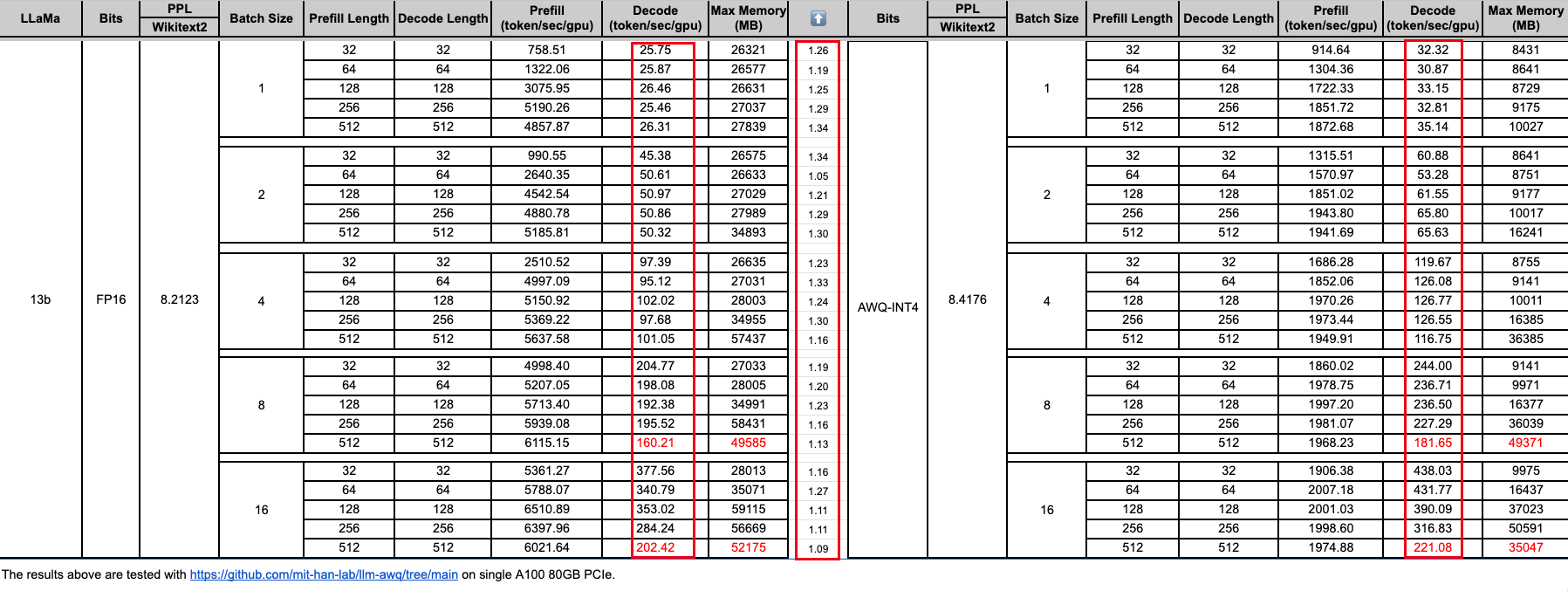
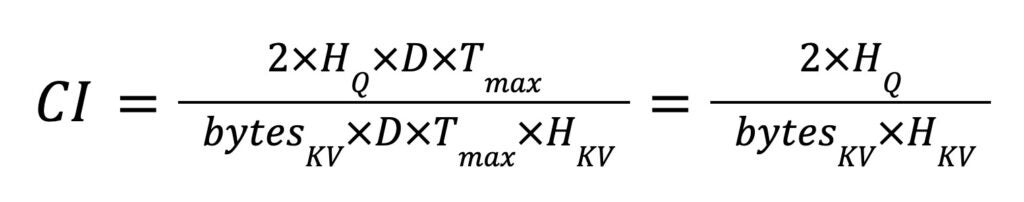Showing 101 of 101on this page. Filters & sort apply to loaded results; URL updates for sharing.101 of 101 on this page
Qwen3-Next 80B Int4 Quant on CPU — No GPU Needed! Easy Tutorial - YouTube
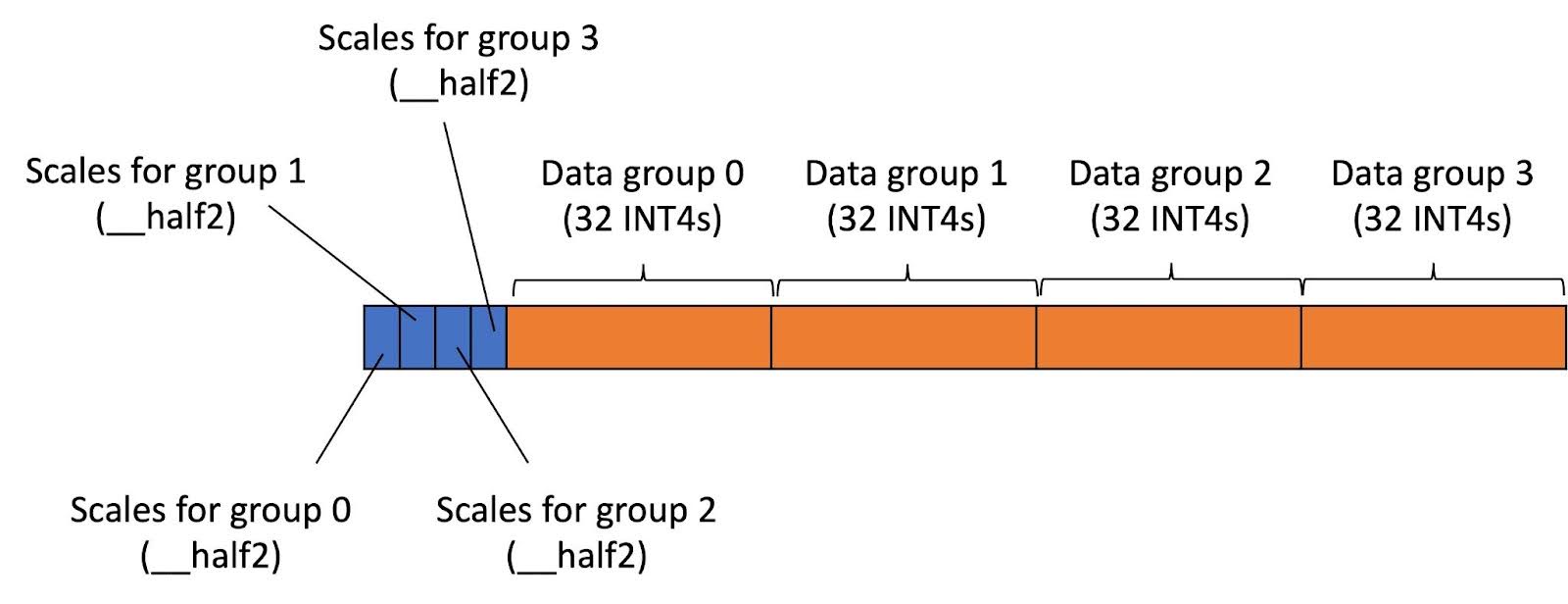
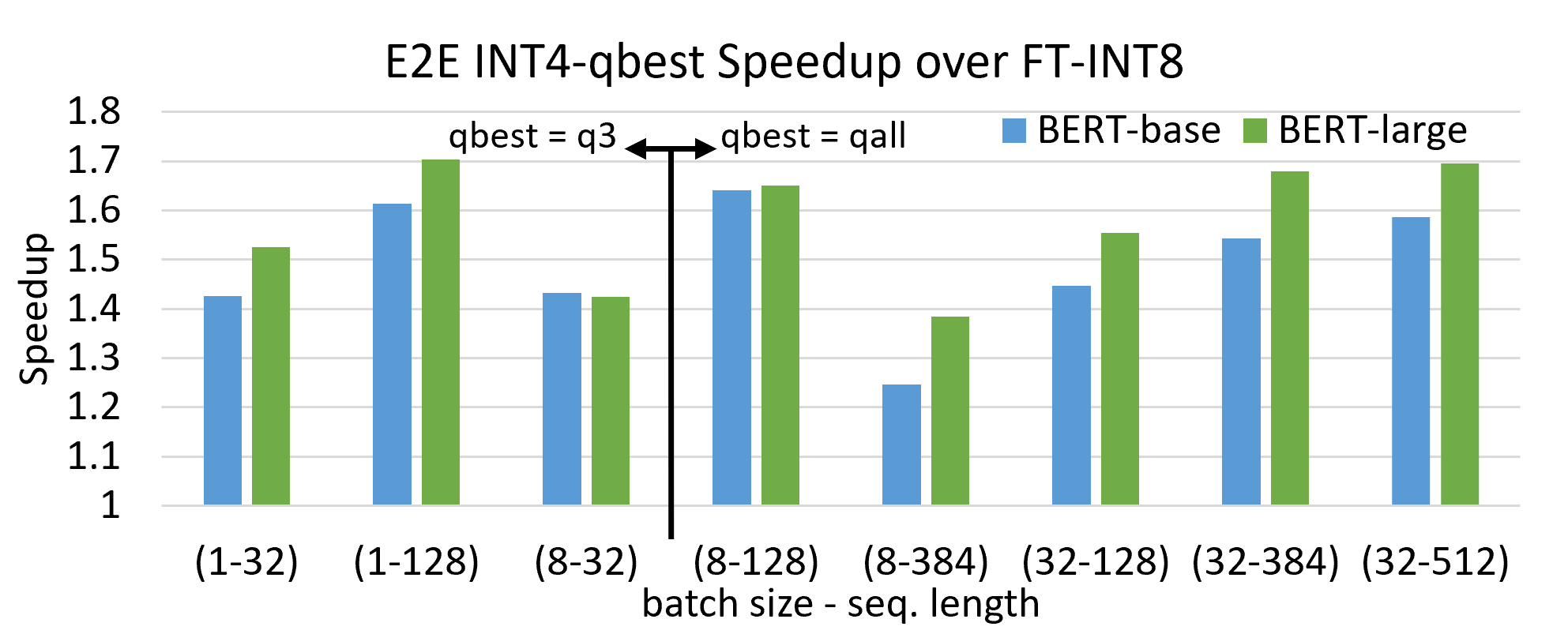
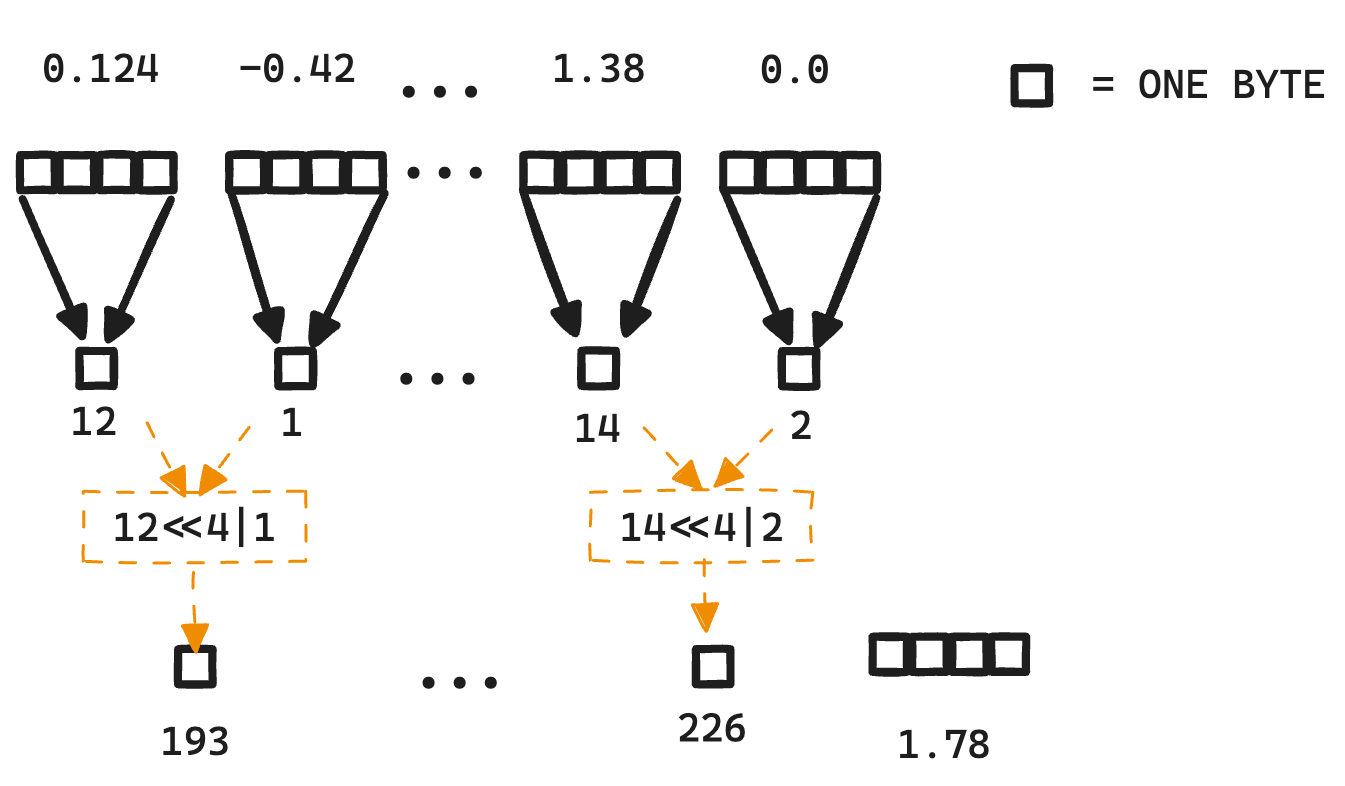
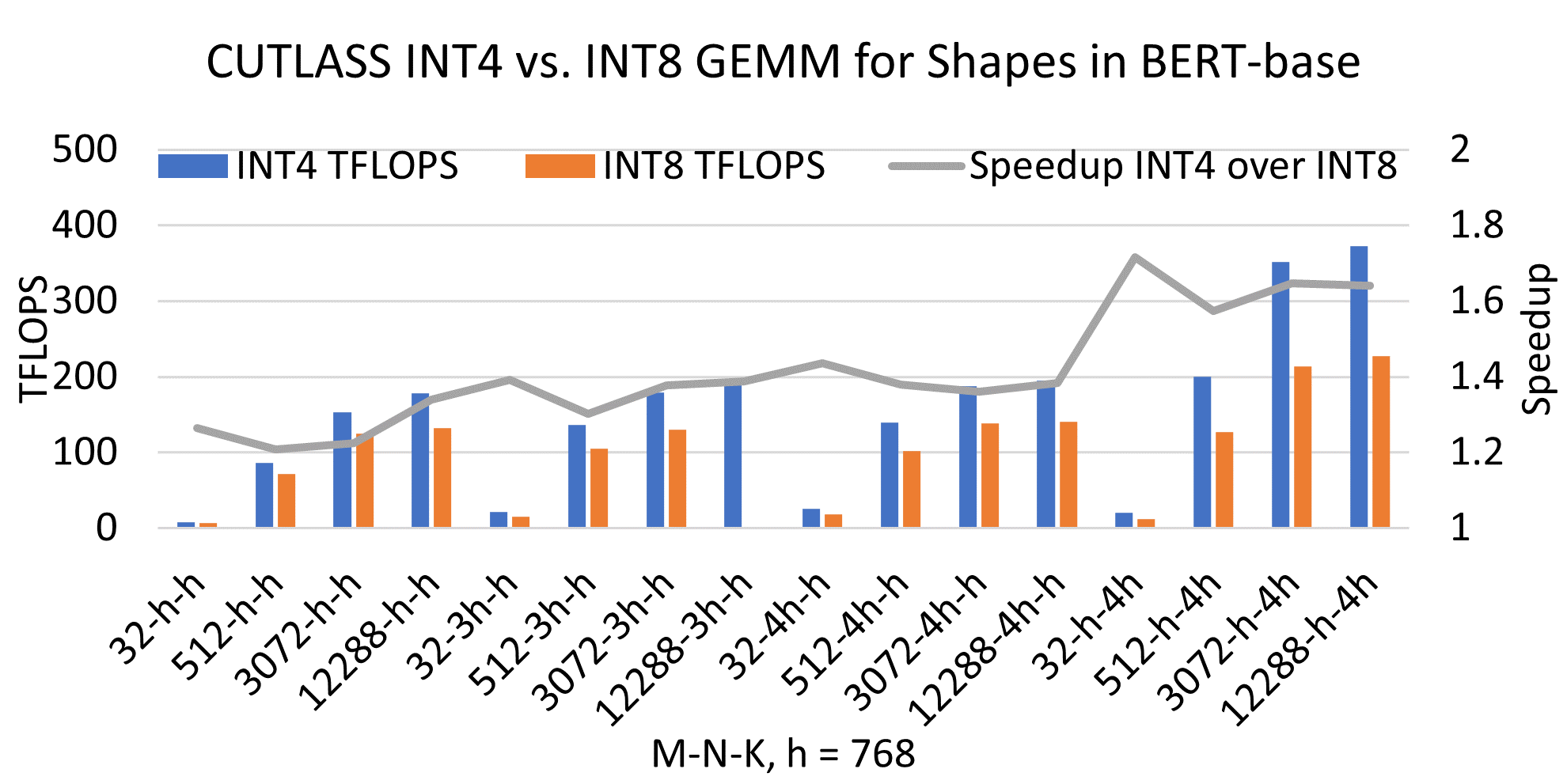
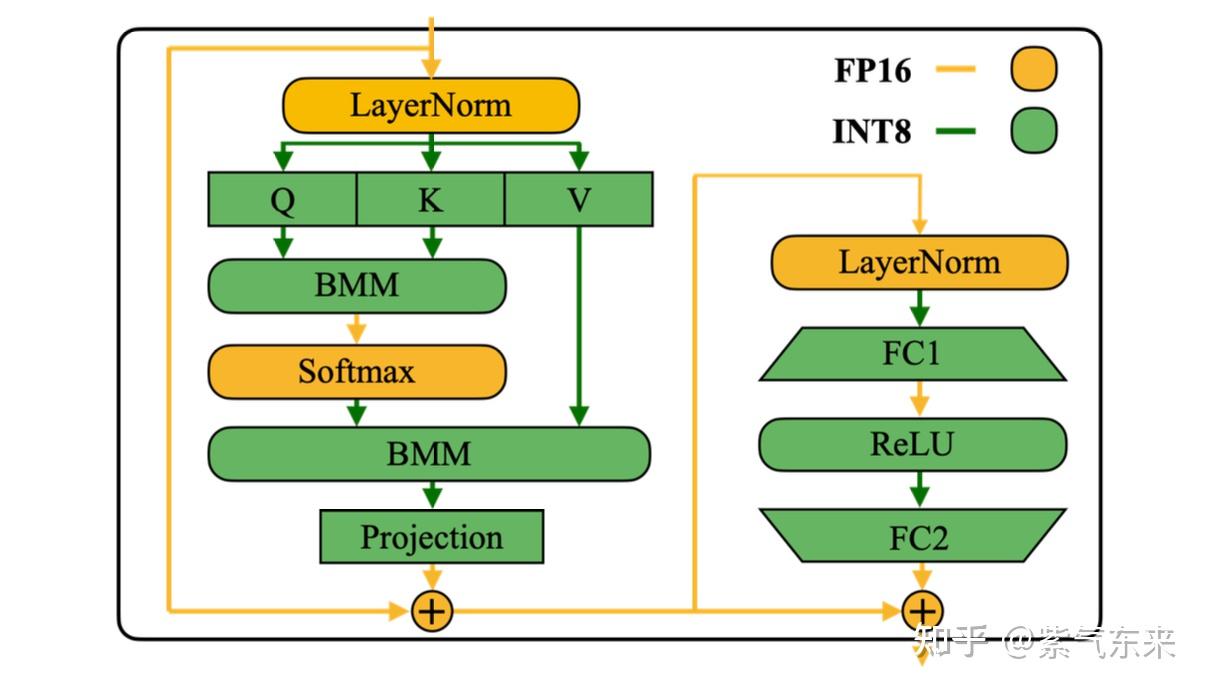
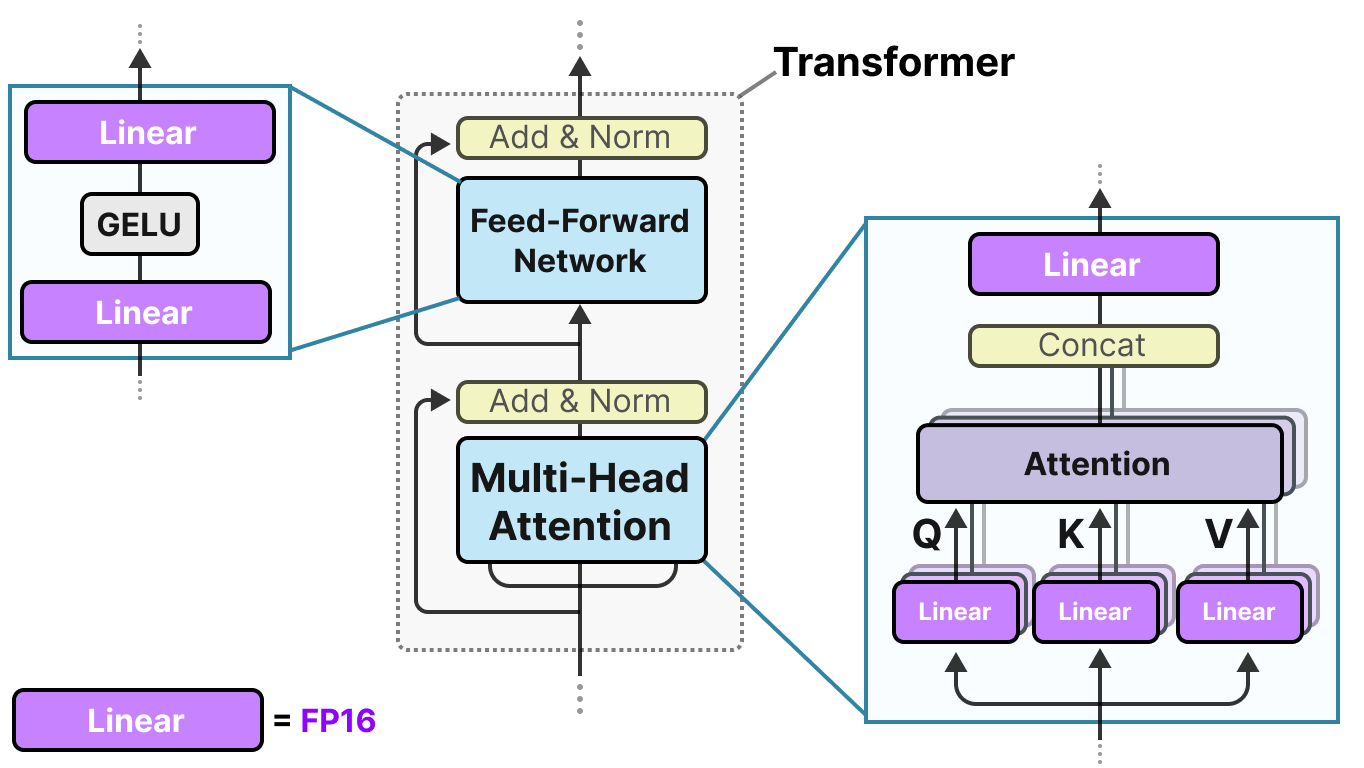
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
QuantTrio/GLM-4.6-GPTQ-Int4-Int8Mix · Quant Size
[2301.12017] Understanding INT4 Quantization for Language Models ...
Understanding Int4 scalar quantization in Lucene - Search Labs
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
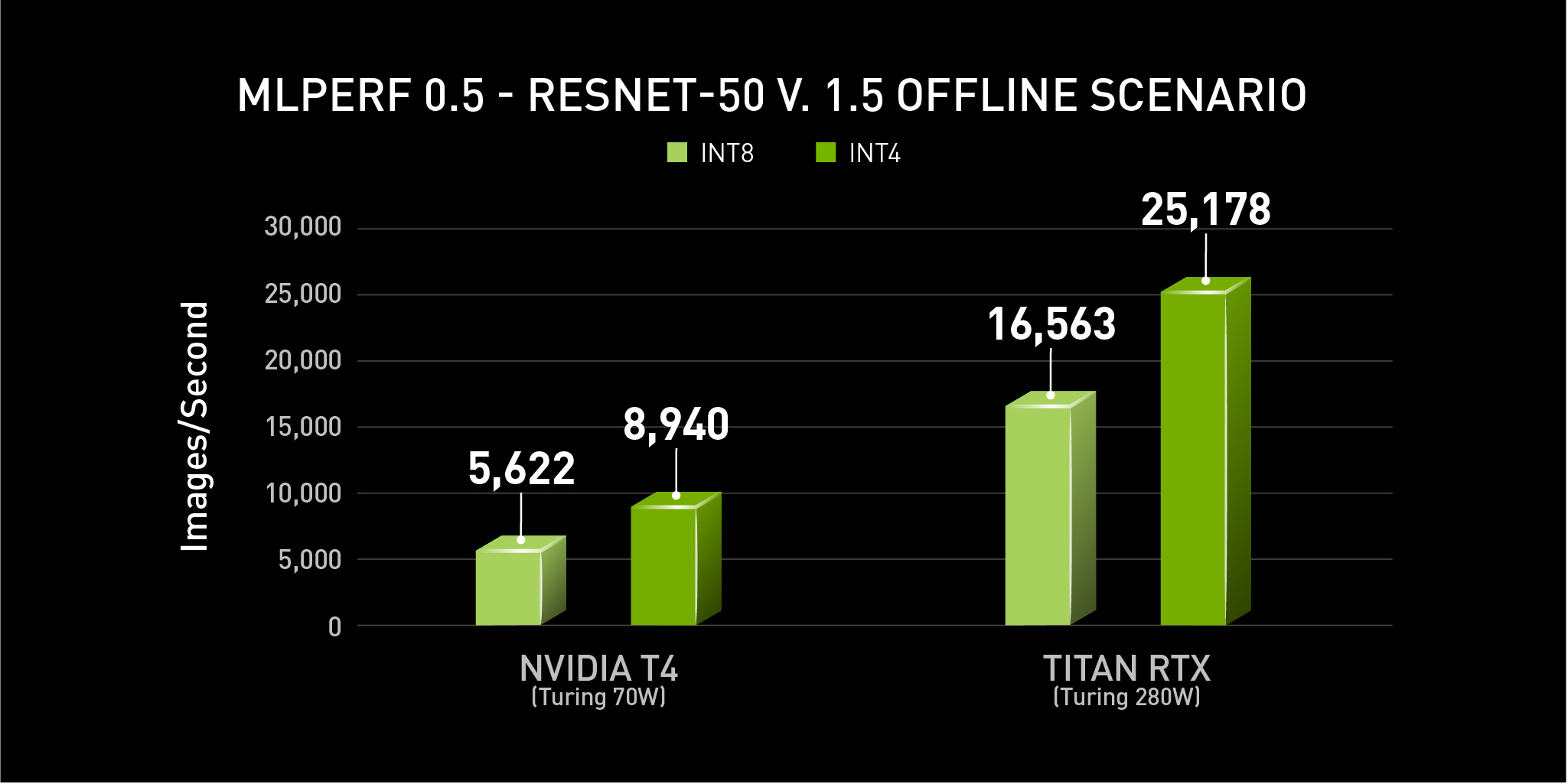
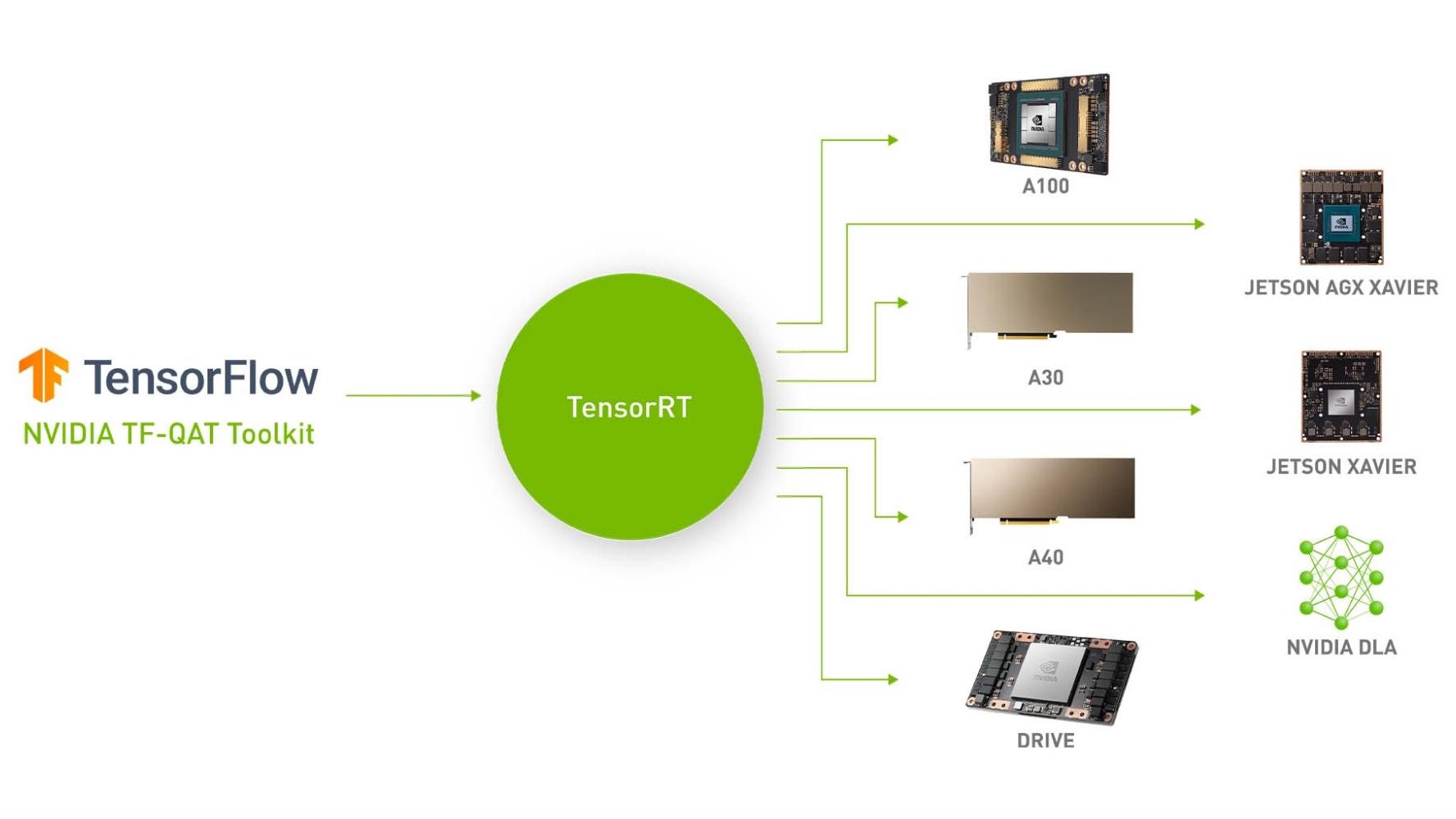
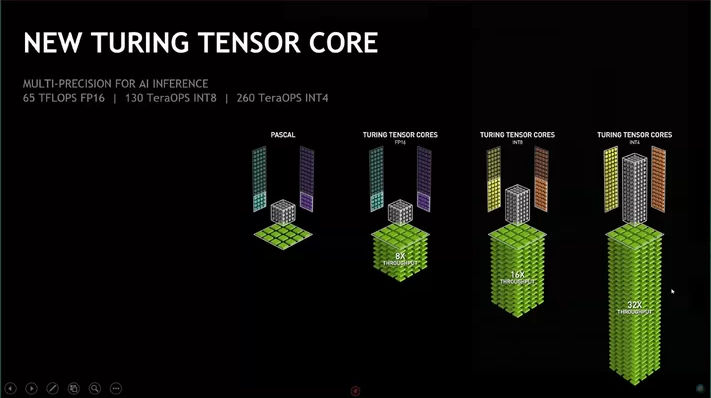
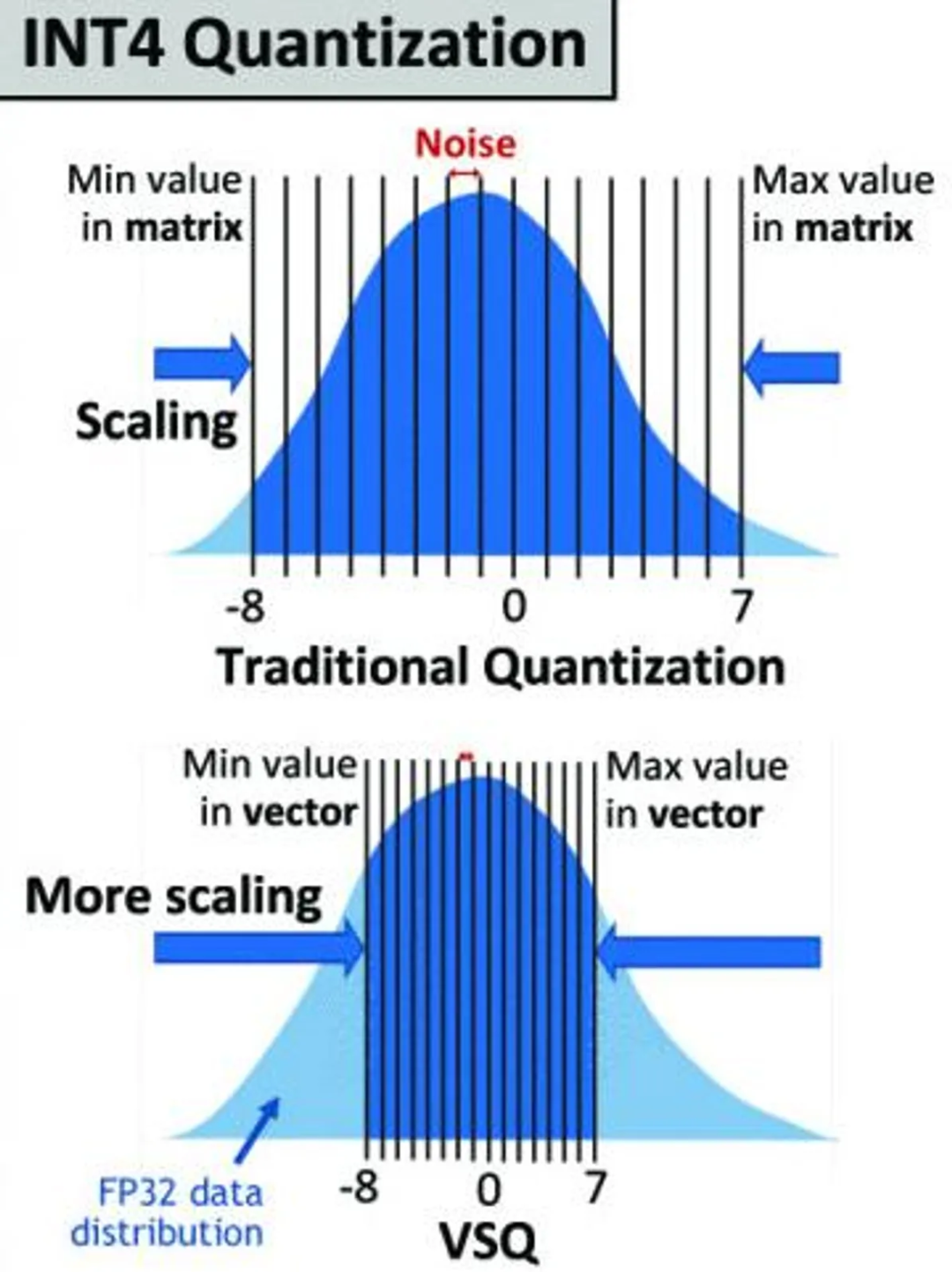
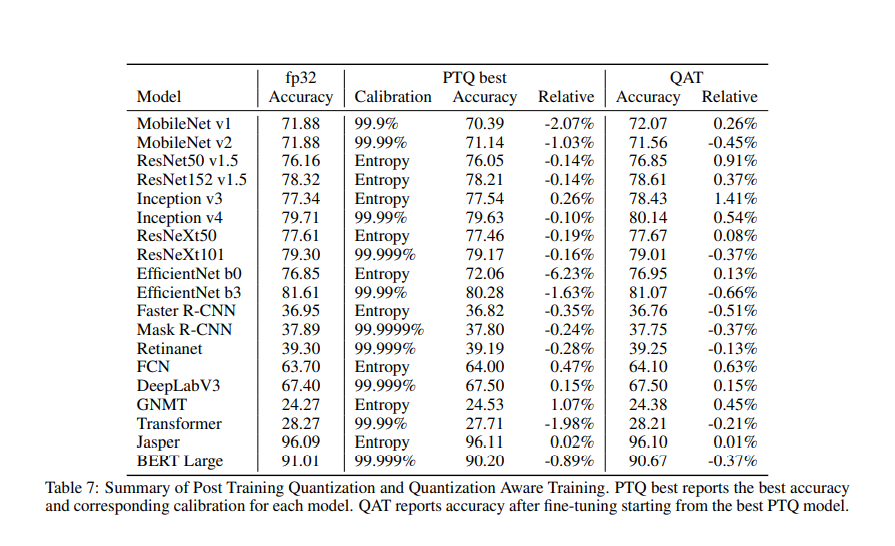
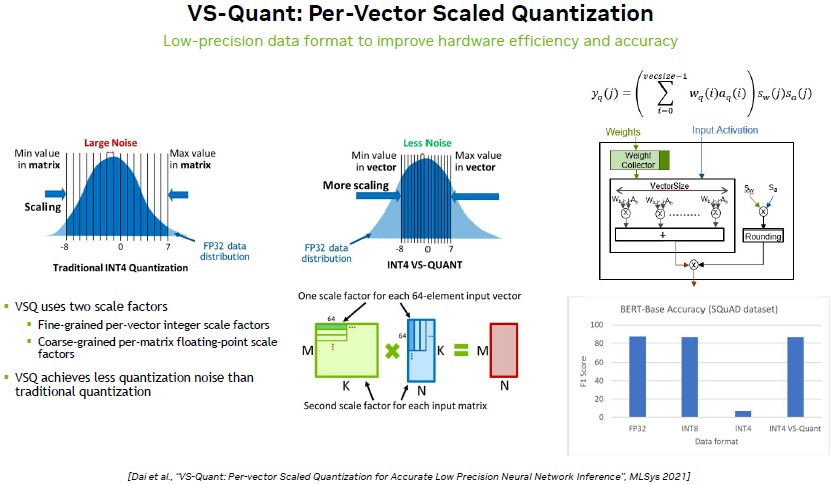
Int4 Precision for AI Inference | NVIDIA Technical Blog
hugging-quants/Meta-Llama-3.1-70B-Instruct-AWQ-INT4 · How to use INT4 ...
INT4 Quantization · Issue #461 · intel/intel-extension-for-pytorch · GitHub
[Quantization] int4 vs fp4 which to choose?
Suite – INT4
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比 - 知乎
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
Quark Quantized INT4 Models - a amd Collection
INT4 Quantization (with code demonstration)
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
Hugging Quants Meta Llama 3.1 70B Instruct AWQ INT4 - a Hugging Face ...
int4 炼丹要术 - 知乎
Why INT4 is presented as performance of GPUs? - Deep Learning - fast.ai ...
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
Quant price breaks out as we predicted: targets 40% surge
Day 62/75 Why INT1 INT4 not used in LLM Quantization | What are ...
Why do ENTERPRISE CUSTOMERS use Int4 Suite? | Most important BENEFITS ...
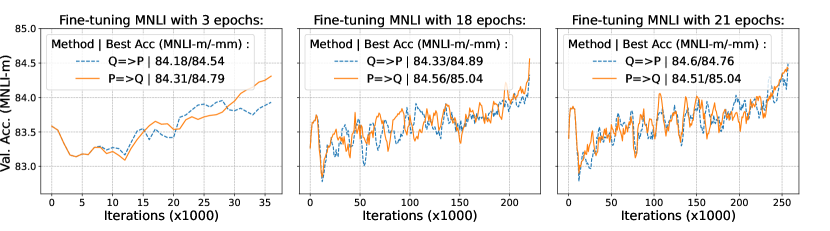
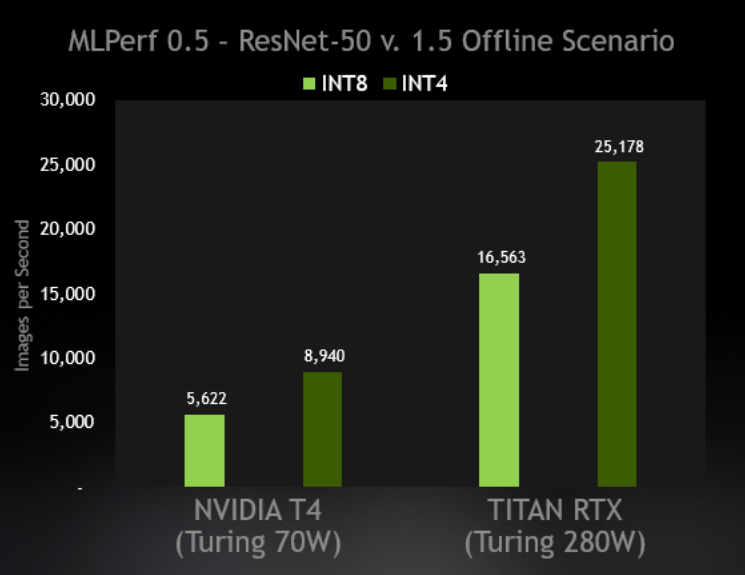
INT4 quantization only delievers 20%~35% faster inference performance ...
Quant Trading Tutorial: A Comprehensive Guide to Algorithmic Trading ...
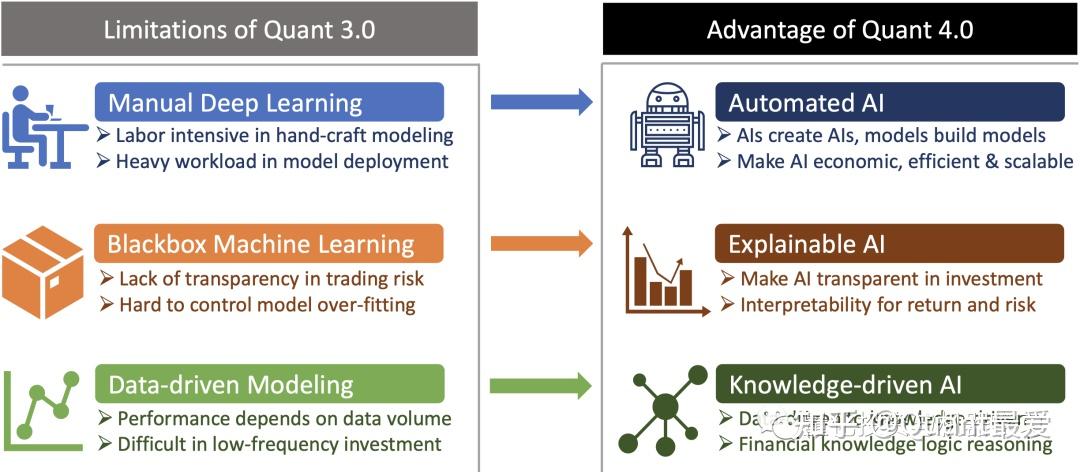
Quant 4.0:你的量化研究处于哪个时代? - 知乎
INT4 Decoding GQA CUDA Optimizations for LLM Inference – PyTorch
INT4 Antibody 0.1mg; Unlabeled:Antibodies, Polyclonal | Fisher Scientific
How To Become a Quant - Career Path and Skills
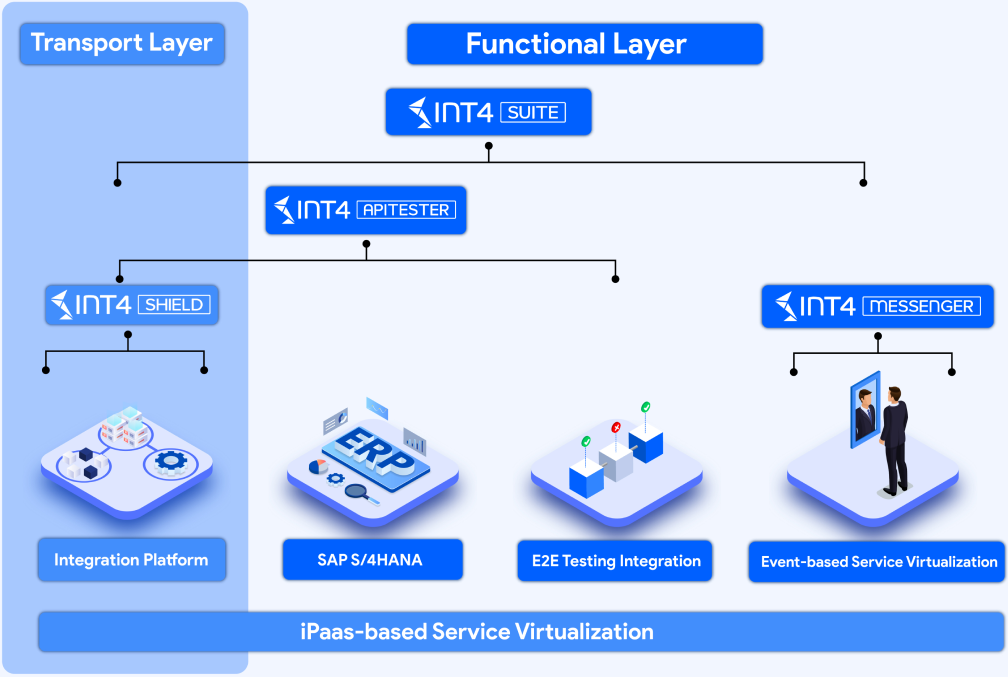
Fast-Tracking Your Migration to SAP Integration Suite with Int4 Shield ...
INT4
INT4 解码 GQA CUDA 优化用于 LLM 推理 – PyTorch - PyTorch 框架
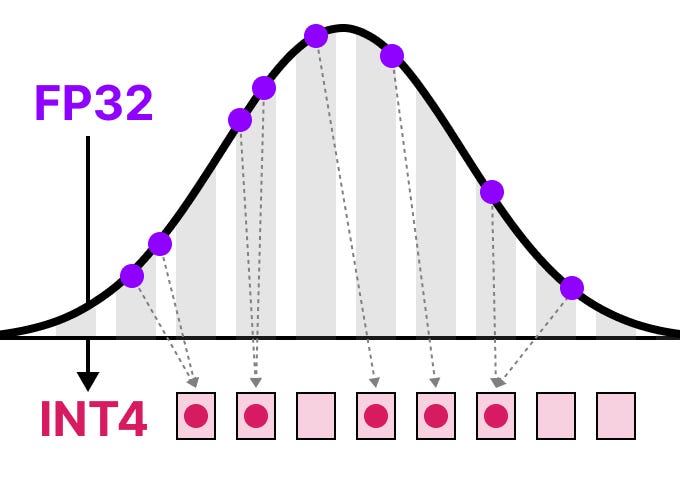
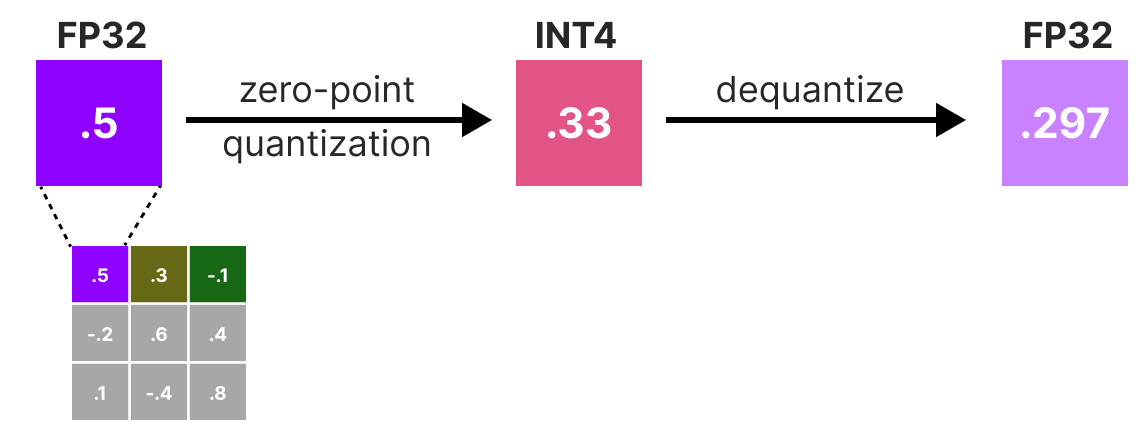
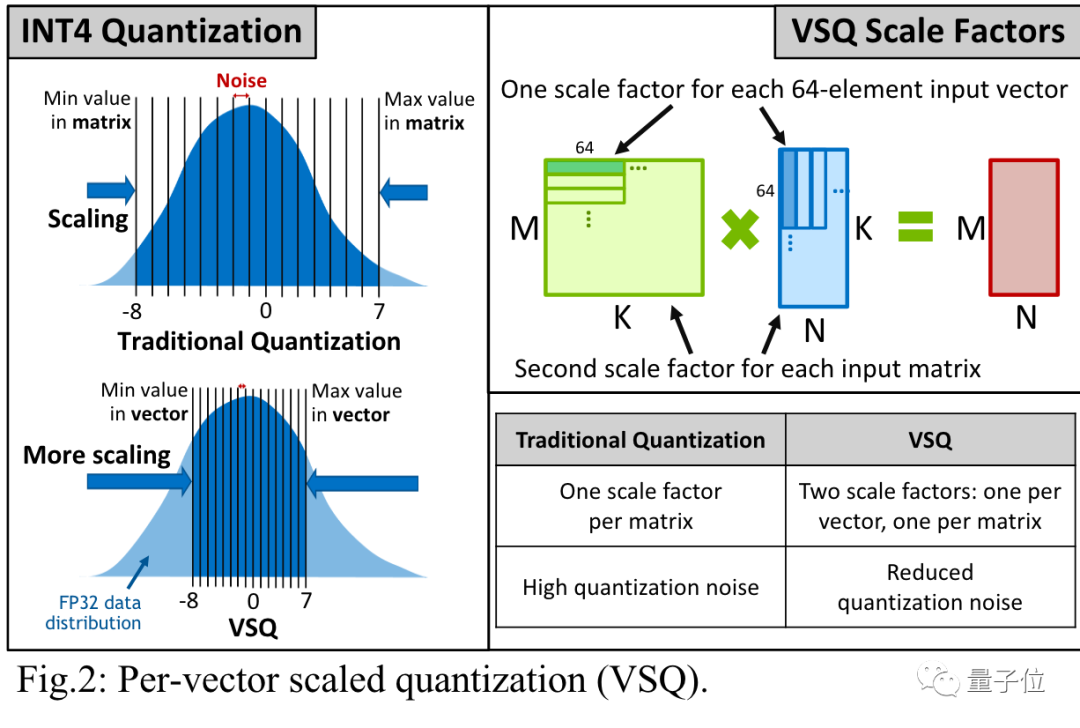
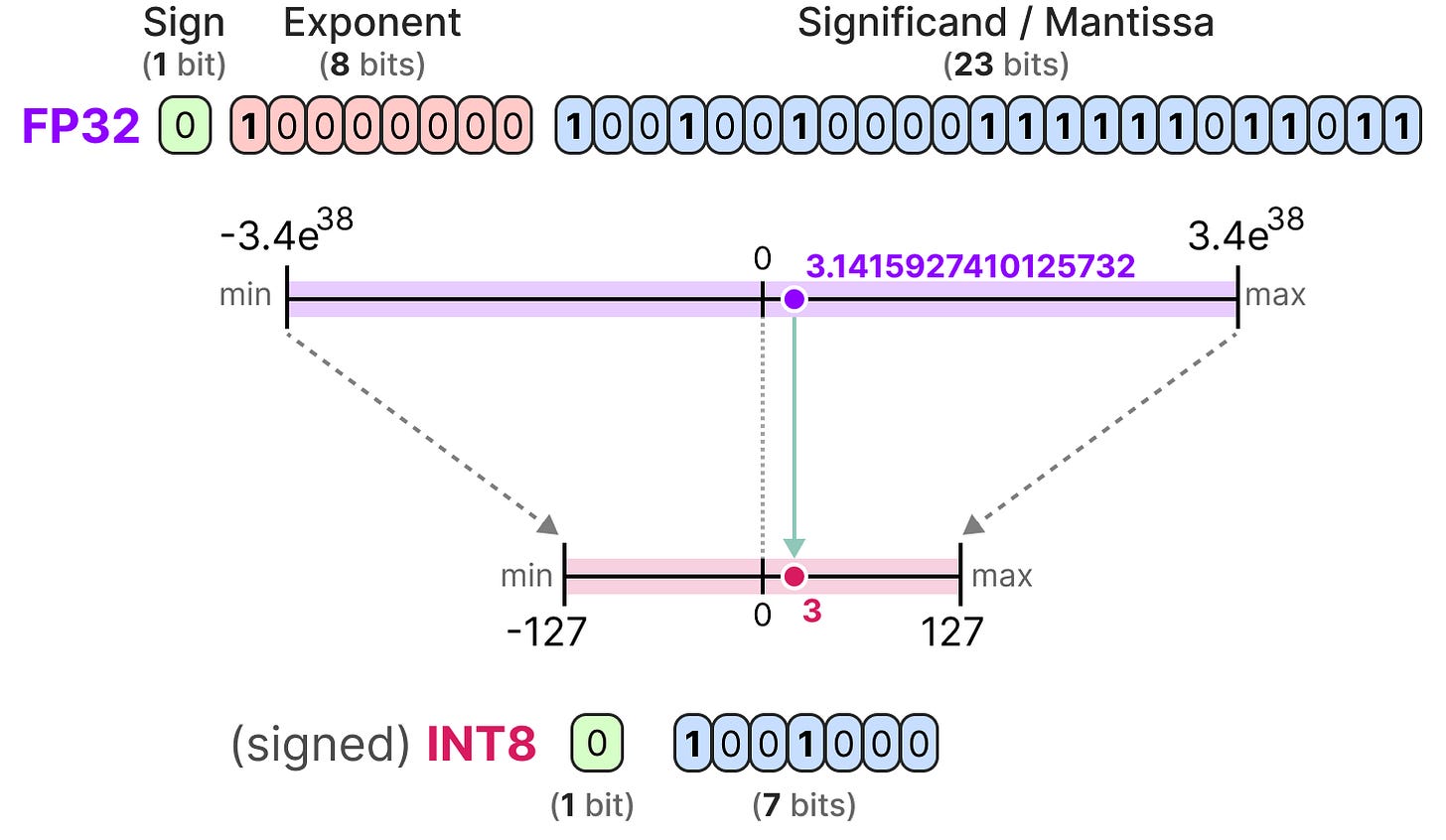
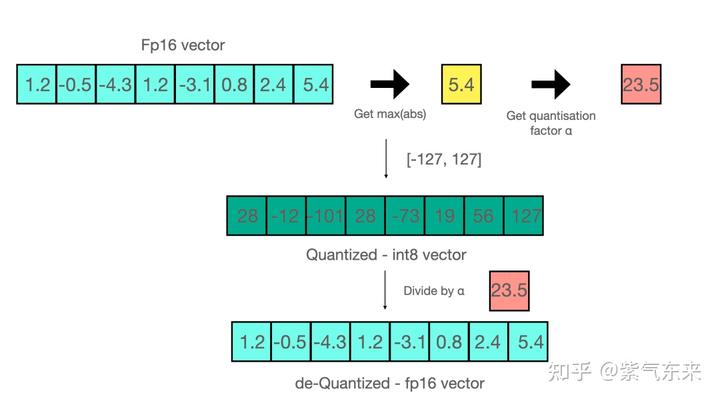
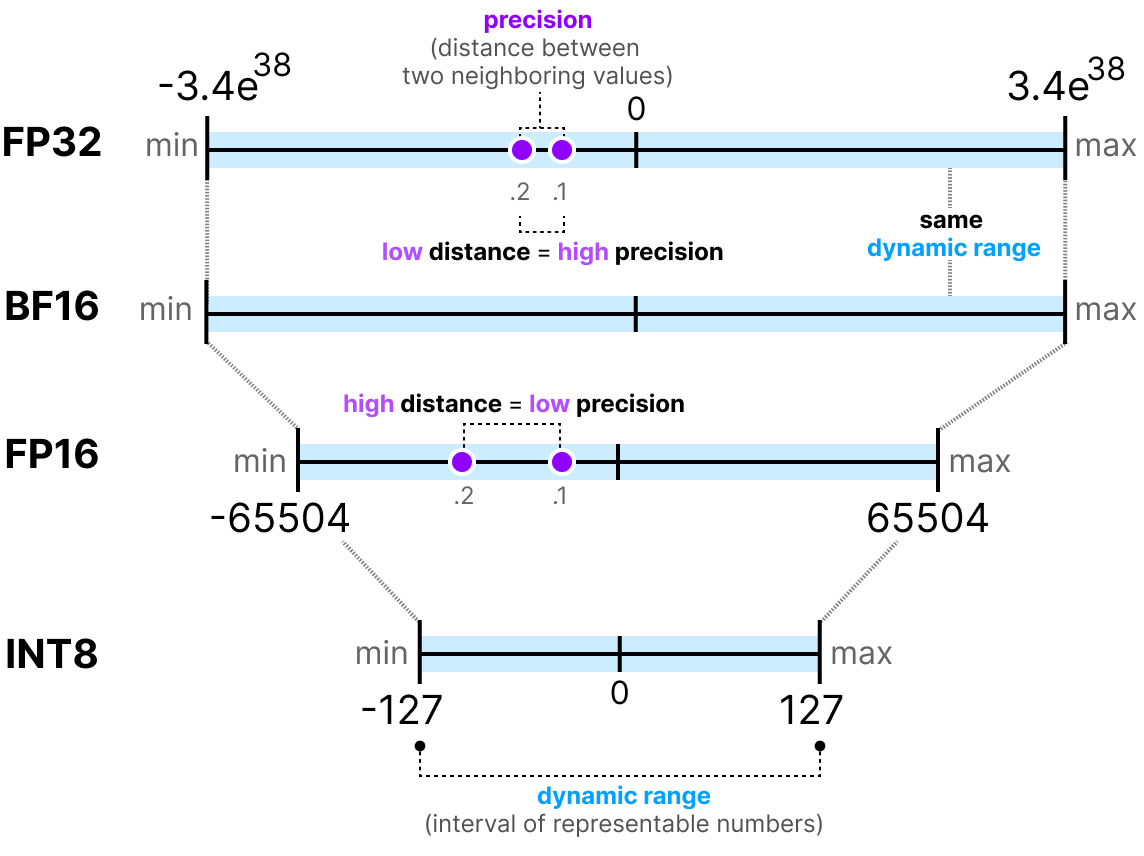
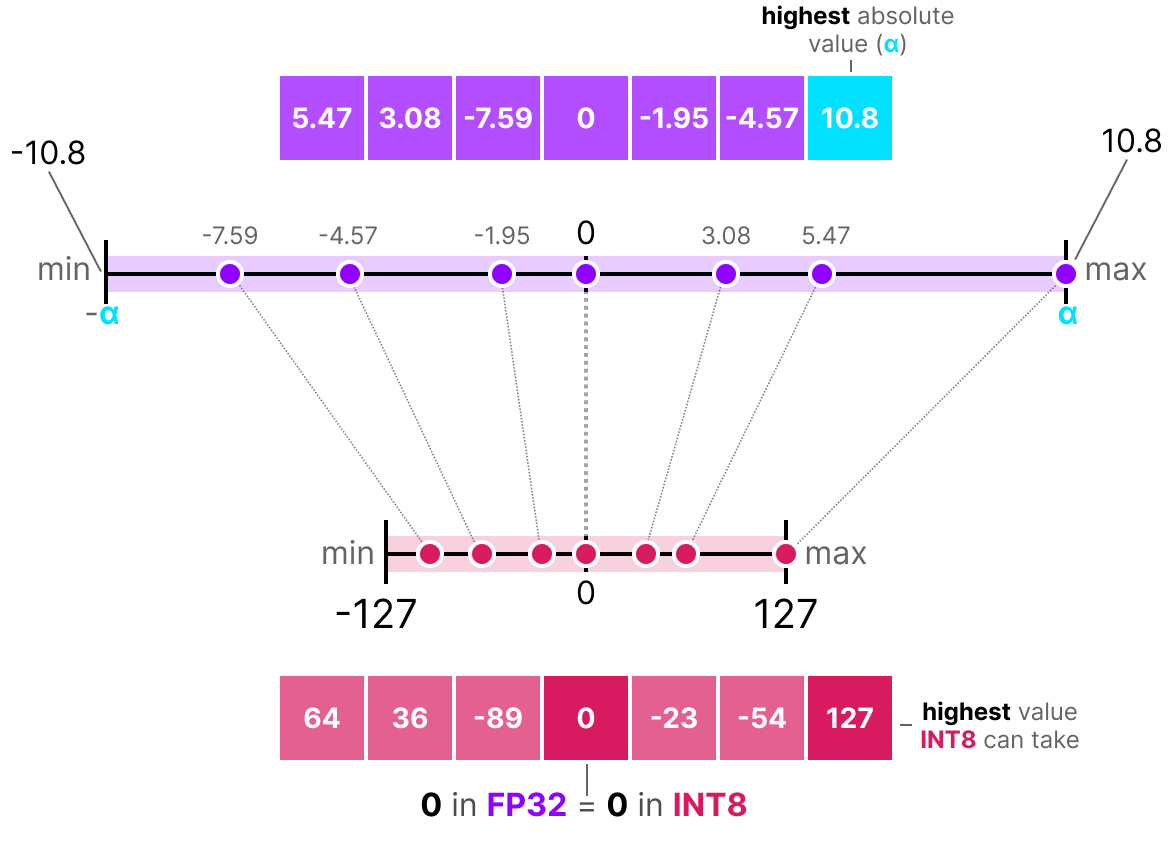
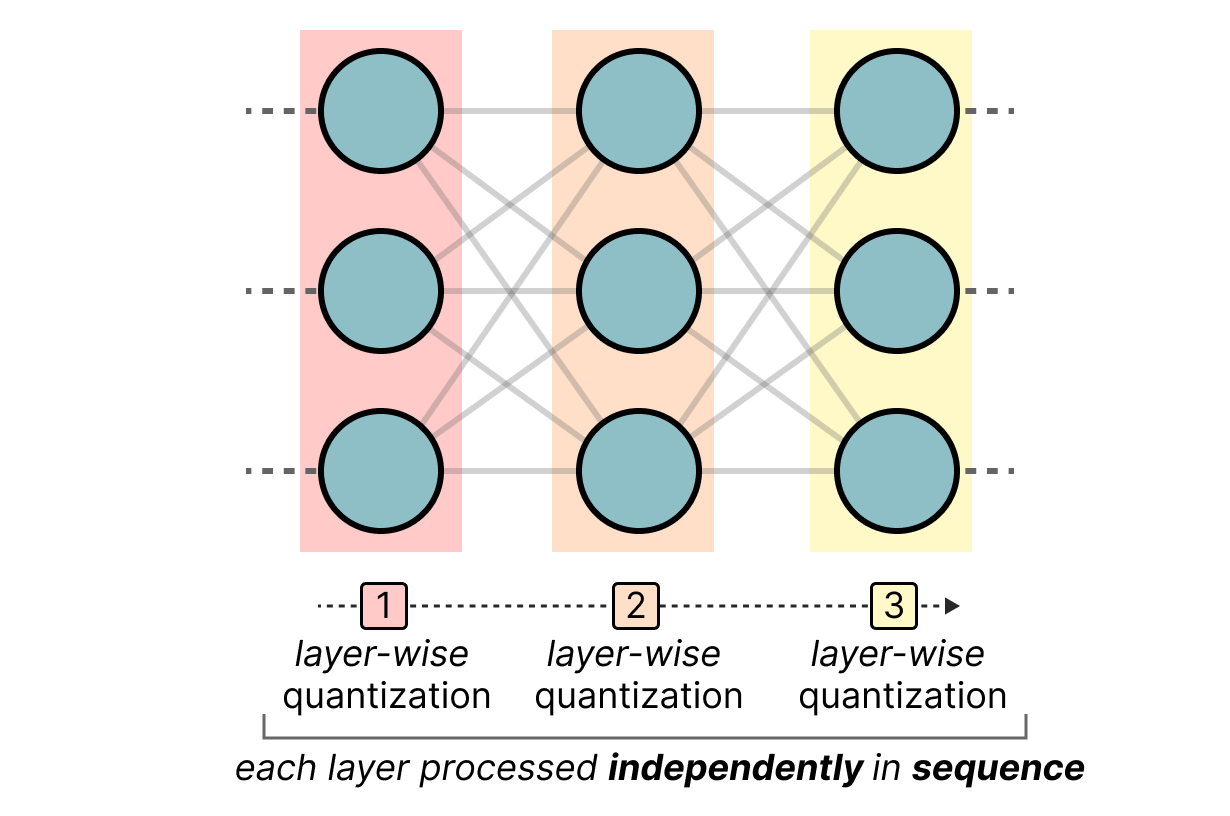
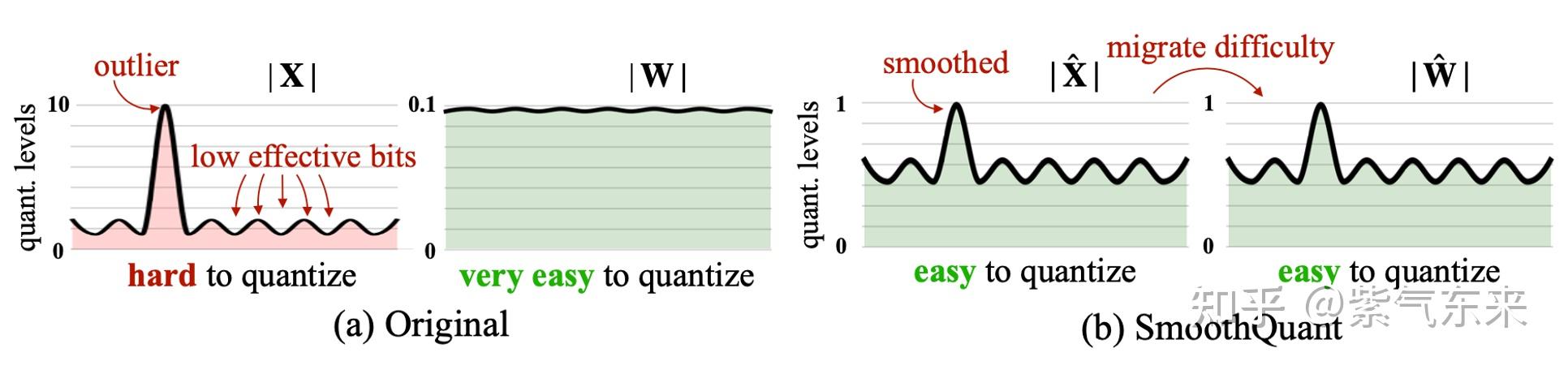
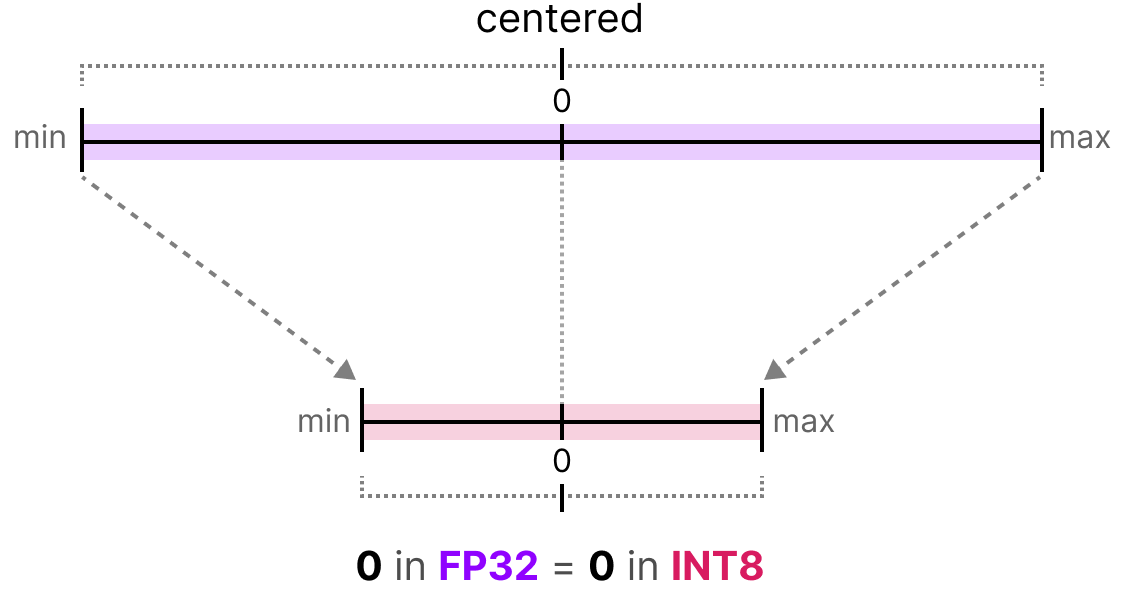
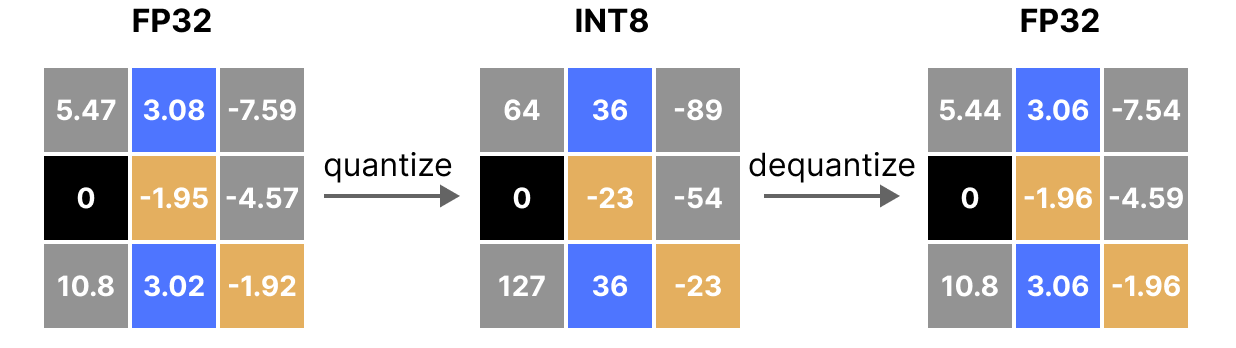
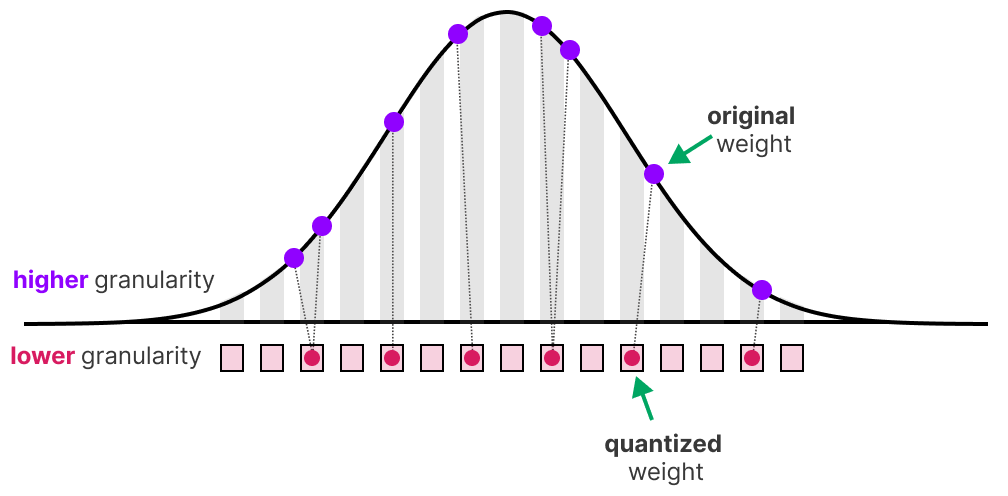
A Visual Guide to Quantization - by Maarten Grootendorst
A Hands-On Walkthrough on Model Quantization - Medoid AI
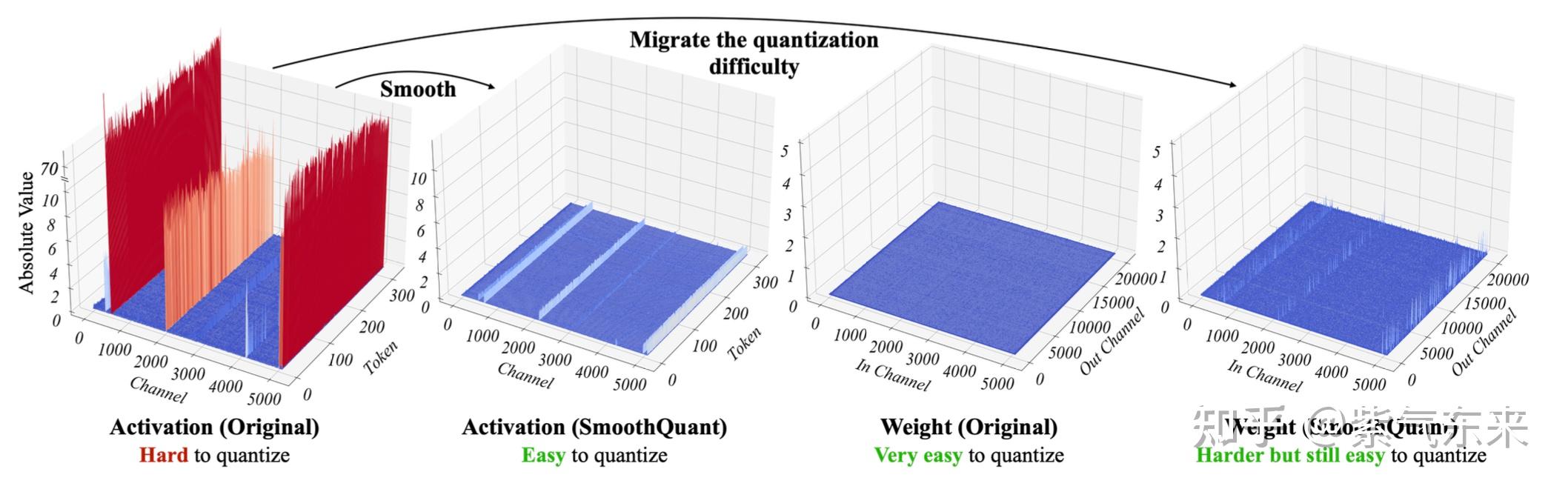
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
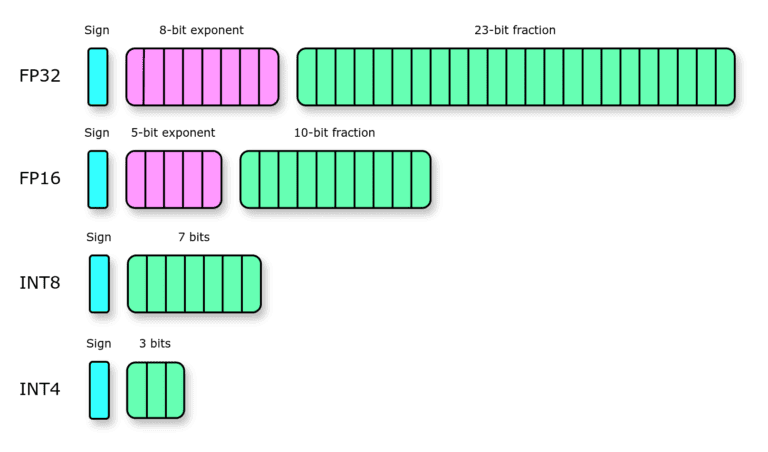
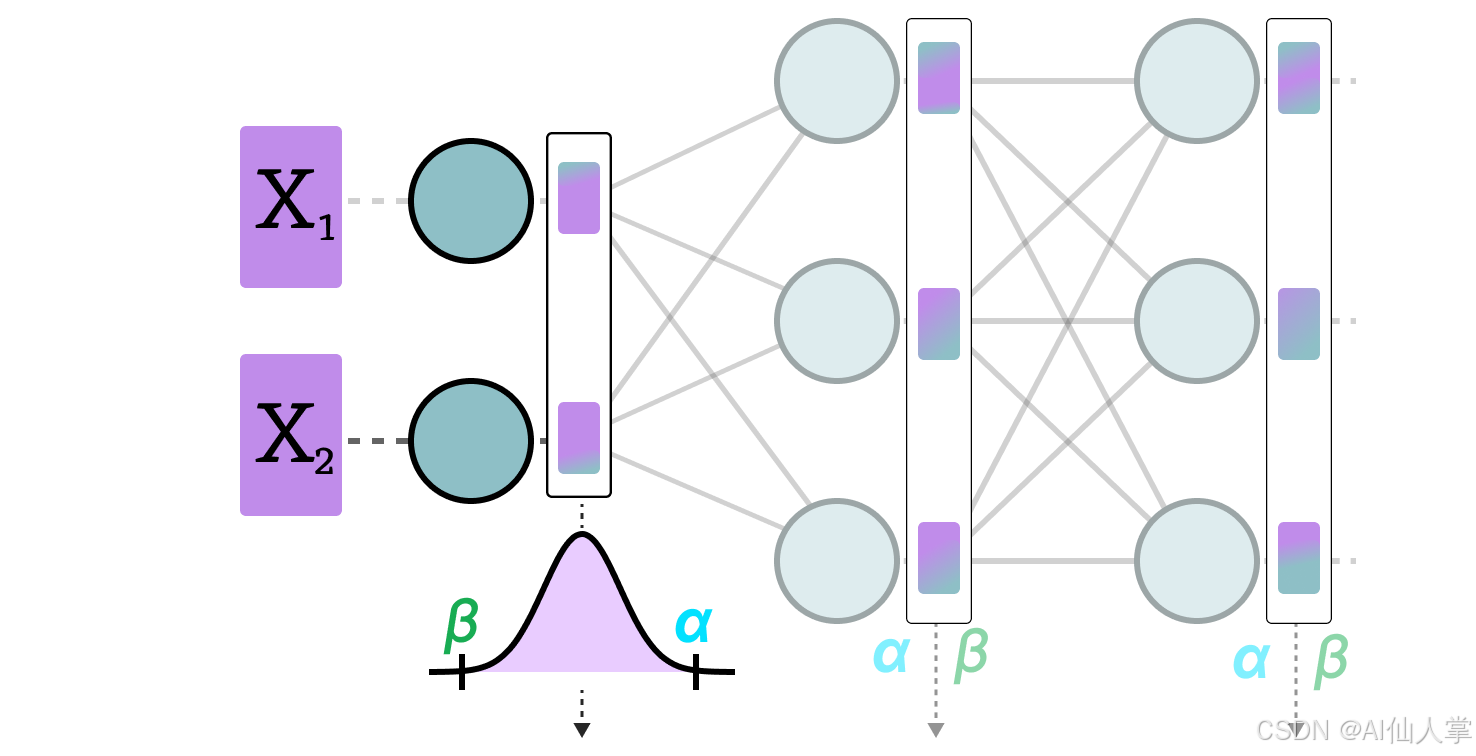
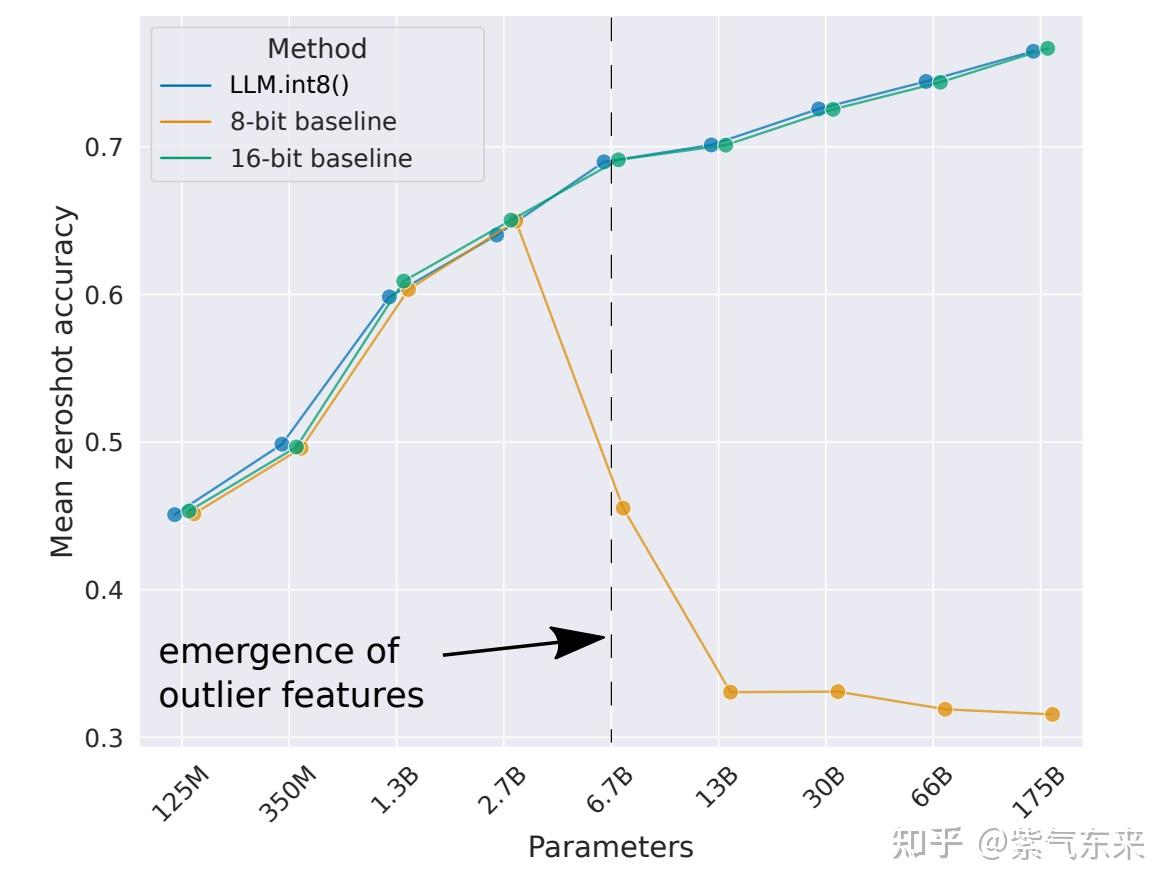
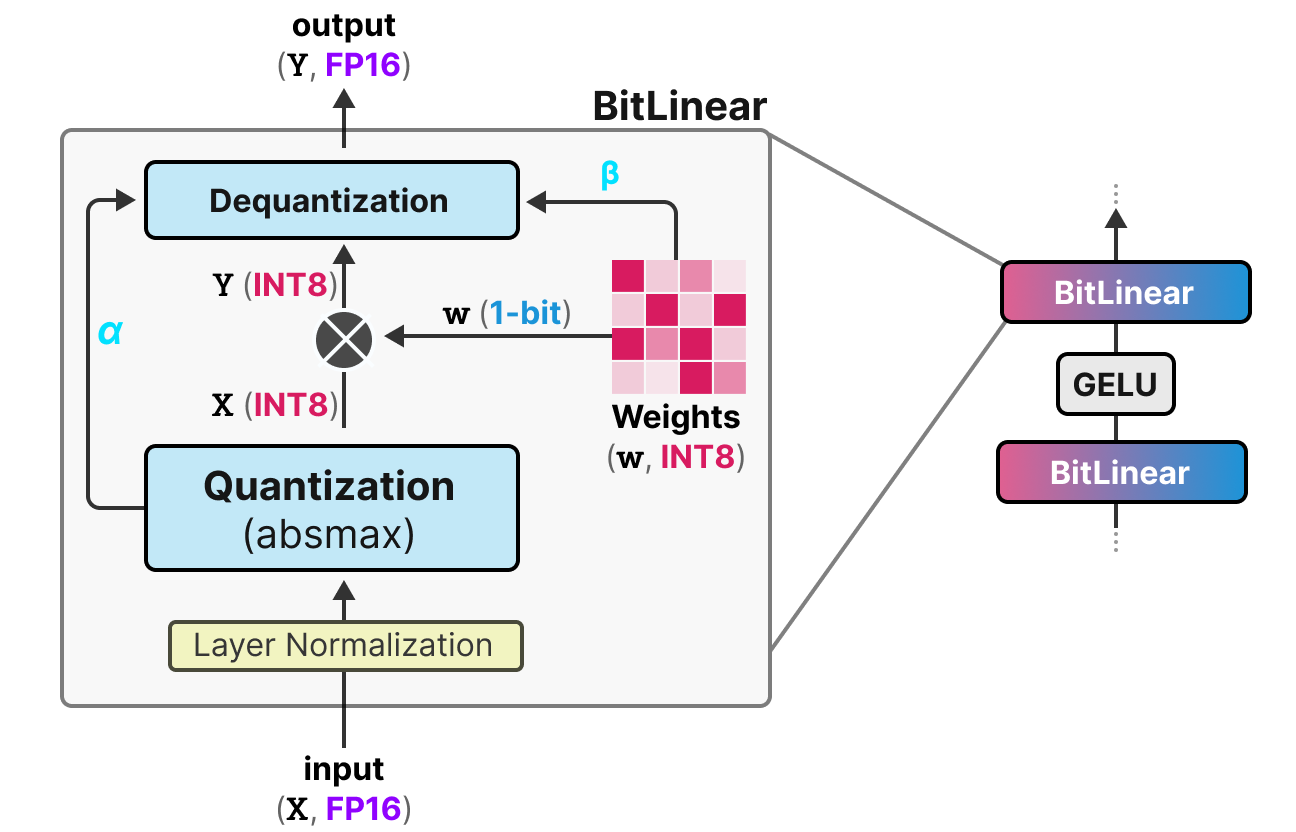
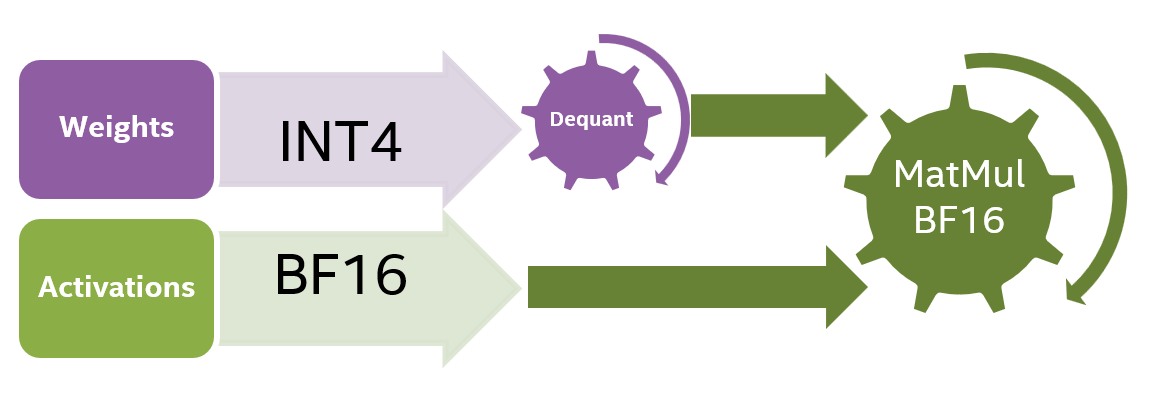
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍 - 知乎
QLoRA、GPTQ:模型量化概述 - 知乎
大语言模型的模型量化(INT8/INT4)技术_int8和int4-CSDN博客
ianZzzzzz/GLM-130B-quant-int4-4gpu at main
QuantTrio/Seed-OSS-36B-Instruct-GPTQ-Int4 · Hugging Face
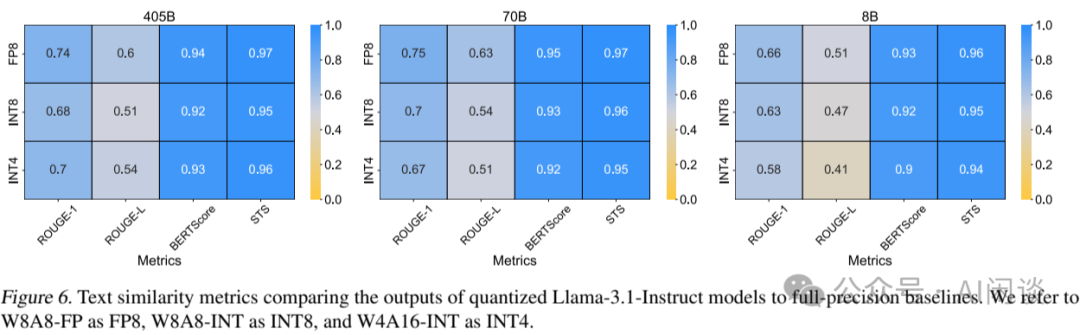
hugging-quants/Meta-Llama-3.1-405B-Instruct-AWQ-INT4 · Hugging Face
hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4 · Source codes to ...
QuantTrio/Qwen3-Coder-480B-A35B-Instruct-GPTQ-Int4-Int8Mix at main
hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 · Update tokenizer ...
hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4 · Can you provide ...
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
hugging-quants/Meta-Llama-3.1-70B-Instruct-AWQ-INT4 · Improve ...
Quantization concepts
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Best SVDQuant-int4-CreArt_Ultimate for Nunchaku 0.2.0 And 0.3.0 Models ...
hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 · The original model ...
meta-llama/Llama-3.2-1B-Instruct-SpinQuant_INT4_EO8 · Hugging Face
ImportError: cannot import name 'int4_weight_only' from 'torchao ...
使用 珞 Optimum Intel 在英特尔至强上加速 StarCoder: Q8/Q4 及投机解码 - HuggingFace - 博客园
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
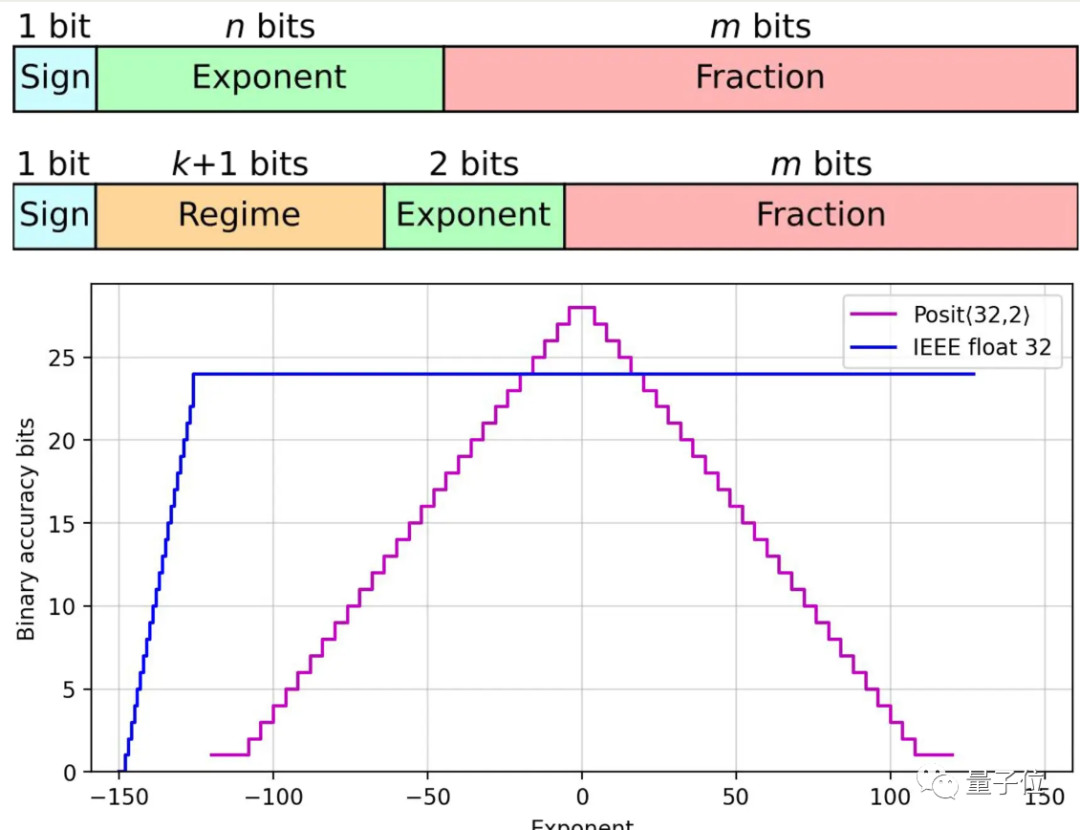
机器学习中的新数学,加速AI训练离不开数字表示方式和基本计算的变革-腾讯云开发者社区-腾讯云
RAG evaluation metrics: A journey through metrics - Search Labs
模型量化(int8)系统知识导读_int4量化-CSDN博客
通义千问大模型Qwen-7B-Chat-Int4运行体验(huggingface+JetsonAGXOrin+int4量化) - 知乎
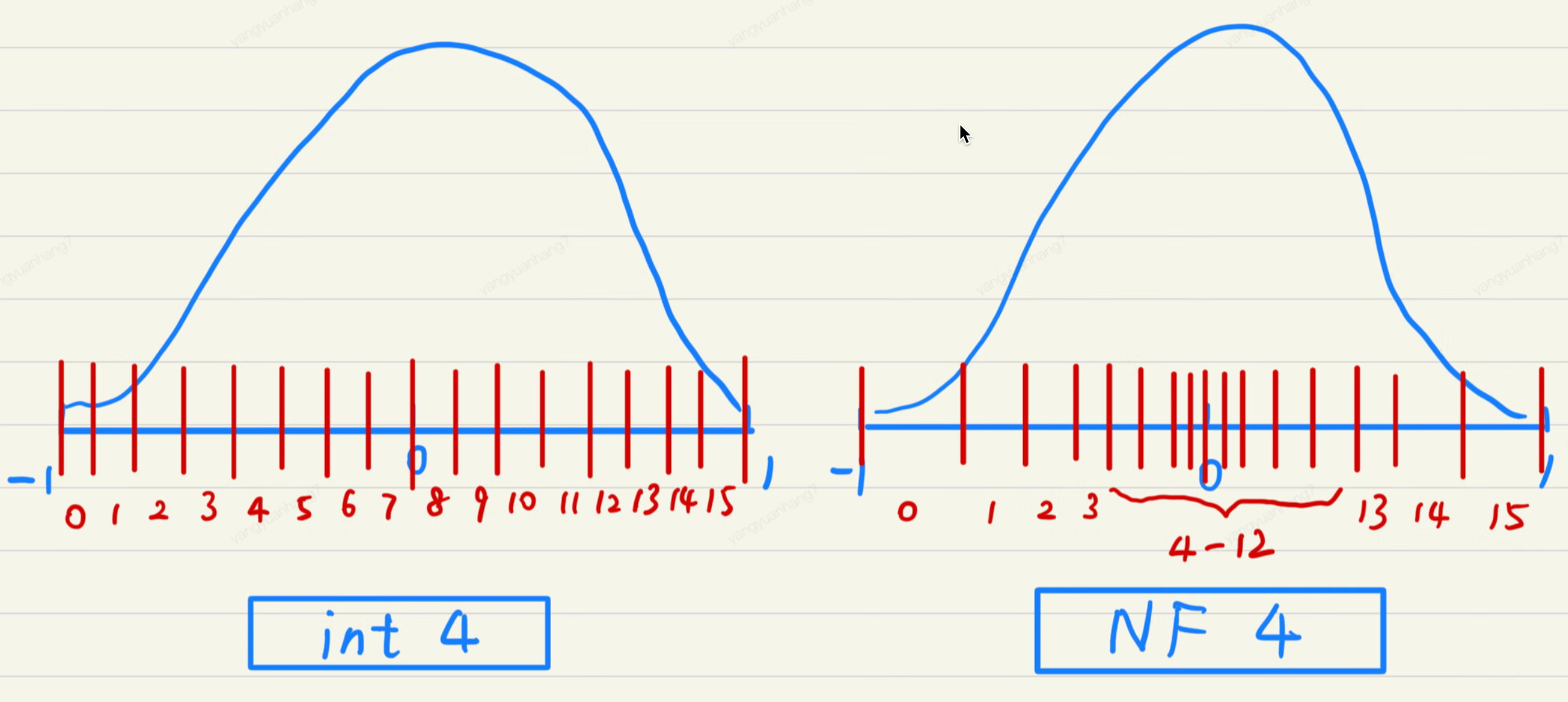
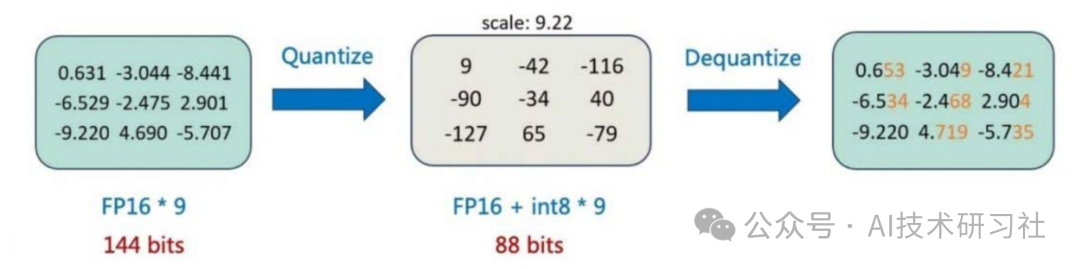
【手撕LLM-QLoRA】NF4与双量化-源码解析 - 知乎
A Peek Into The Future Of AI Inference At Nvidia
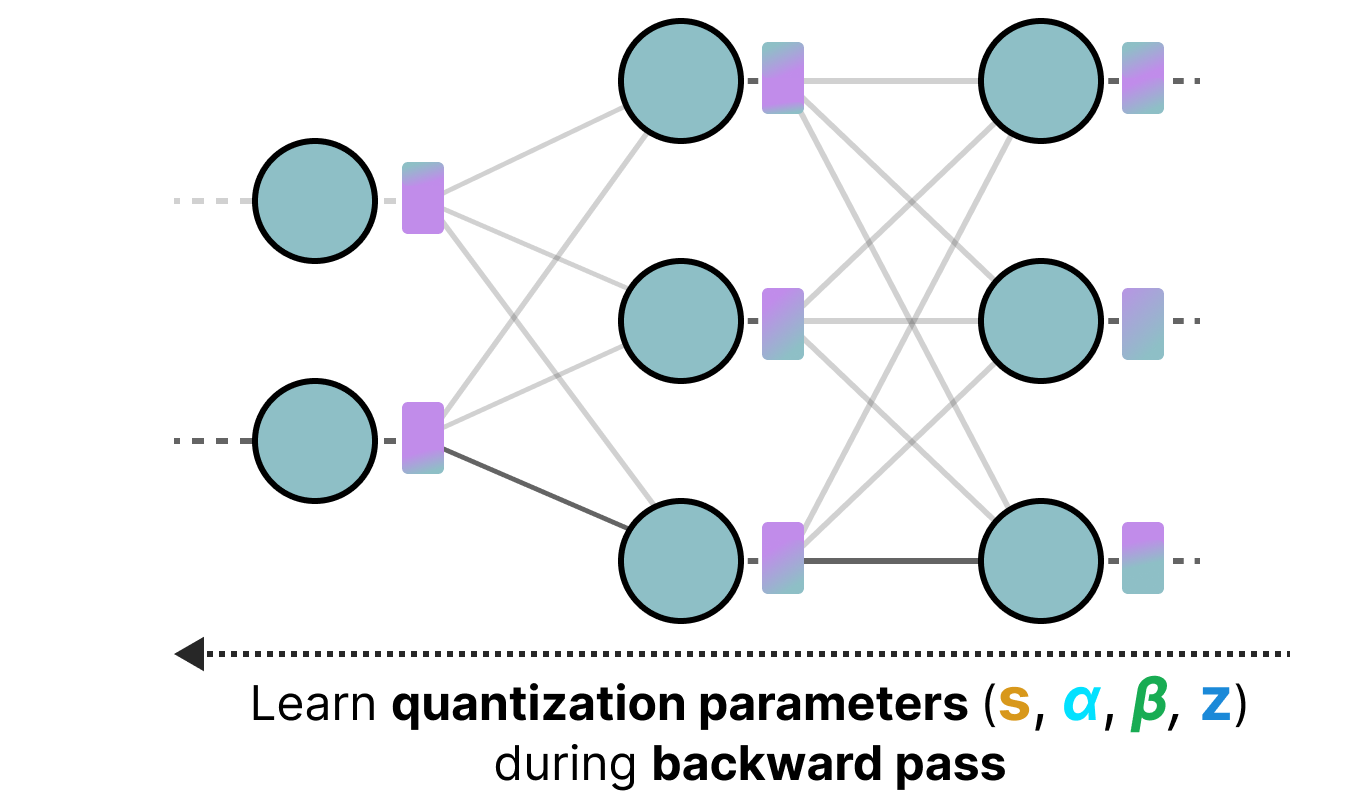
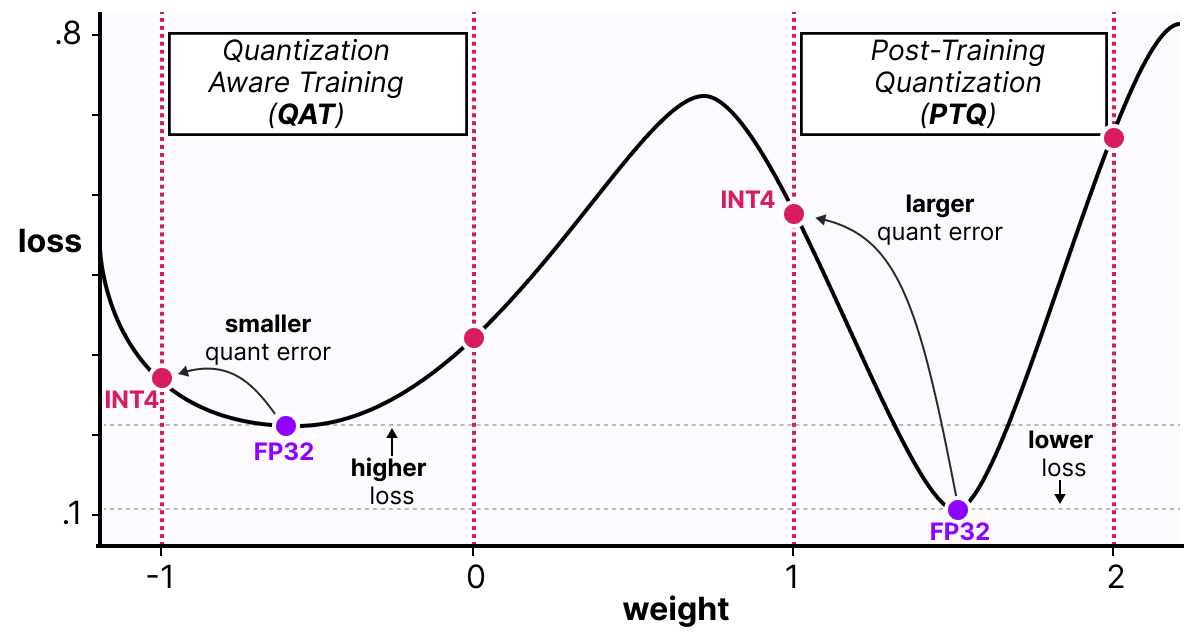
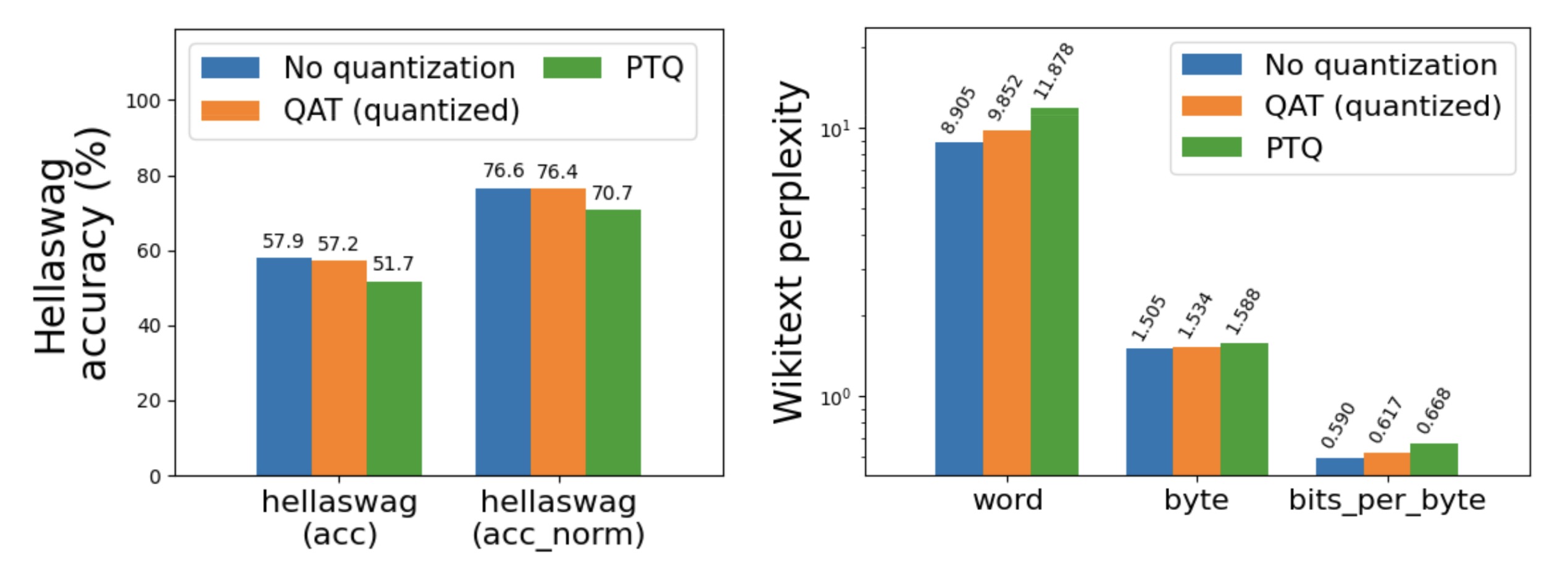
Quantization-Aware Training for Large Language Models with PyTorch ...
mit-han-lab/svdq-int4-flux.1-depth-dev · Hugging Face
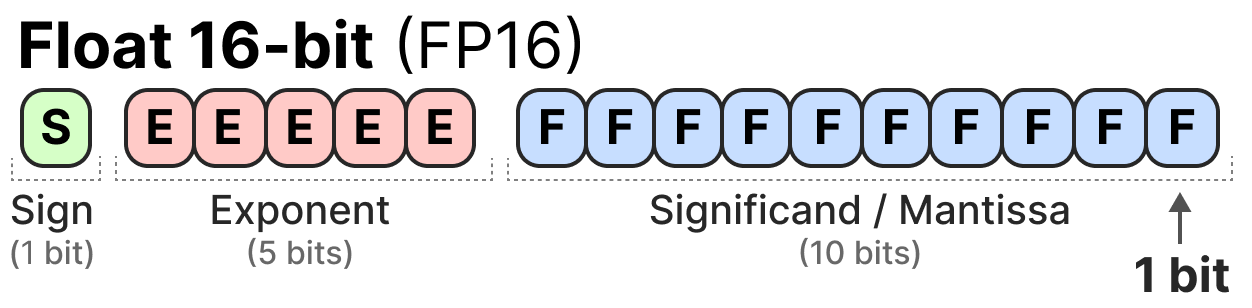
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
Quantization Bits at Amanda Okane blog
骁龙AI进化论:推开新世界的大门
meta-llama/Llama-3.2-1B-Instruct-SpinQuant_INT4_EO8 · Adding ...
Int4:Lucene中的标量量化更进一步-腾讯云开发者社区-腾讯云